

Why
do we say the things we do?
Ada
Tam
“Please
pass me the pork… I mean fork.” Slips-of-the-tongue can
be embarrassing. However, by analysing the types of errors
and when they are produced, researchers have gained insight
into how they occur and a better understanding of the
mechanisms that underlie word production.
Have
you ever noticed that speech blunders tend to be real
words or at least sound like one? Research has shown that
speech errors seem to obey the “rules of the language”
that determine what sounds like a real word and what does
not.1 People learn
through experience about sound patterns that occur in
language. These patterns are stored in each person’s lexicon,
which acts as a ‘mental dictionary’. Guidance provided
by the lexicon makes uttering ‘impossible’ sound combinations
unlikely since the sounds are unfamiliar. Sound-based
errors are also more likely to occur in longer and infrequently
used words.
Archibald
Spooner was famous for making classic speech blunders,
such as “You have hissed all my mystery lectures”. Spoonerism
is an example of how speech errors can be real words.
Another way can involve problems in selecting the correct
word. For instance, you might say, “Where is my tennis
bat?” instead of, “Where is my tennis racquet?”2 One possible explanation is that abstract
words that are difficult to form a mental image of are
more likely to be replaced by words with easier to form
mental images.
A dominant model of word production
Dell proposed a model that describes word selection
as a two-step process (see Fig. 1).3
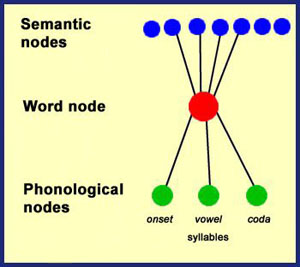 Fig. 1. Basic hierarchical structure of Dell's model |
Imagine the linguistic mind as a network of wires connecting light bulbs to one another. These light bulbs are ‘nodes’ that represent words, such as ‘cat’, or the sounds that form the word, such as ‘c’. Activation spreads from one ‘node’ to another, so when one light bulb switches on, light bulbs connected to it will switch on, too. The level of activation, or the brightness of each light bulb, indicates the extent of that node participating in the word production. Several nodes can also be active at the same time, and activation can cascade either in a top-down (meaning-word-sound) or bottom-up (sound-word-meaning) direction.4
Dell’s model can help explain mixed errors, those that share both sound features and meaning with the intended word (see Fig. 2).
|
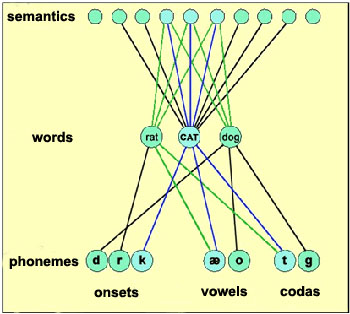
When the ‘cat’ light bulb switches on, so do the light bulbs for the semantic meanings and the sounds that form the word ‘cat’. So, the words ‘dog’ and ‘rat’ are activated since they share a semantic domain with ‘cat’. However, as ‘rat’ shares sounds with ‘cat’ whereas ‘dog’ does not, the ‘rat’ light bulb is brighter than ‘dog’. Therefore, you are more likely to say the word ‘rat’ than the word ‘dog’.5
Top-down and bottom-up connections may be forming a type of filter that screens out non-words.4 This filtering might explain why speech errors to be real words. If sound patterns are stored in the lexicon, it is possible that impossible sound sequences are being filtered out as well.
Bottom-up processing can help explain certain sound-based speech errors. For example, you may have problems articulating the correct sound when there is ‘competition’ between phonemes or syllables. This is what makes tongue-twisters, such as “she sells sea-shells on the seashore”, so difficult to say. Also, speech errors tend to occur more frequently when people neglect to “think before they speak”.3
How useful is this model?
Although recording speech errors has been a useful method of determining what types of errors occur whilst speaking, the data may not be entirely accurate. For instance, the listener could misinterpret what has been said. Problems can arise when the speaker and listener use different dialects; vowels may be mistaken for one another, and the same applies for consonants. There is also a suggestion that in speech error collections, there is a bias toward detecting errors located at the beginning of the word.6
Furthermore, Levelt and his colleagues have challenged the dependency on speech error data, arguing that only reaction-time studies can provide reliable evidence for word production models.7 They proposed the alternative computational model, WEAVER++ (Word-form Encoding by Activation and VERification). The design is very similar to Dell’s model, the difference being that it is able to predict the speed of word production.
Nevertheless,
speech error analysis has been useful. Identifying the
situations where these errors are produced has made it
possible to develop models to explain the processes involved
in word production. Although studying slips-of-the-tongue
alone is incomplete, it has provided valuable insight
into the way words are generated in everyday speech.
See
OnSET's The
science of reading
Glossary
Coda syllable: Phonetic sound at the end of the word
Lexicon: A store of detailed information about words
Onset syllable: Phonetic sound at the beginning of the word
Phoneme: A basic speech sound conveying meaning
Spoonerism: A type of speech error that occurs when the sounds at
the beginning of words are exchanged and the resulting
errors are real words
References
1. Dell, G.S., Reed, K.D., Adams, D.R., & Meyer, A.S. (2000). Speech Errors, Phonotactic Constraints, and Implicit Learning: A Study of the Role of Experience in Language Production. Journal of Experimental Psychology: Learning, Memory, and Cognition, 26, 1355–1367.
2. Harley, T.A., & MacAndrew, S.B.G. (2001). Constraints Upon Word Substitution Speech Errors. Journal of Psycholinguistic Research, 30, 394–417.
3. Eysenck, M.W., & Keane, M.T. (2001). Cognitive Psychology, 4th Edition. Hove, UK: Psychology Press, Taylor & Francis.
4. Schwartz, M.F., Saffran, E.M., Bloch, D.E. & Dell, G.S. (1994). Disordered Speech Production in Aphasic and Normal Speakers. Brain and Language, 47, 52–88.
5. Levelt, W.J.M. (1999). Models of word production. Trends in Cognitive Sciences, 3, 223–232.
6. Cutler, A. (1981). The reliability of speech error data, Linguistics, 19, 560–582.
7. Levelt, W.J.M., Roelofs, A., & Meyer, A.S. (1999). A theory of lexical access in speech production. Behavioral and Brain Sciences, 22, 1–75.
Further Reading
Harley, T.A. (2001). The psychology of language: From data to theory, 2nd Edition. Hove, UK: Psychology Press, Taylor & Francis.
OnSET is an initiative of the Science Communication Program
URL: http://www.onset.unsw.edu.au/ Enquiries: onset@unsw.edu.au
Authorised by: Will Rifkin, Science Communication
Site updated: 7 Febuary, 2006 � UNSW 2006 | Disclaimer
CRICOS Provider Code: 00098G
OnSET is an online science magazine, written and produced by students.
![]()
OnSET Issue 6 launches for O-Week 2006!
![]()
Worldwide
Day in Science
University
students from around the world are taking a snapshot
of scientific endeavour.
Sunswift
III
The UNSW Solar Racing Team is embarking
on an exciting new project, to design and build the
most advanced solar car ever built in Australia.
![]()
Outreach
Centre for Sciences
UNSW Science students can visit your school
to present an exciting Science Show or planetarium
session.
![]()
South
Pole Diaries
Follow the daily adventures of UNSW astronomers
at the South Pole and Dome C through these diaries.
News in Science
UNSW is not responsible for the content of
these external sites